반응형
카이제곱 분포(χ2 분포)는 정규분포를 따르는 모집단에서 k개의 샘플을 뽑았을 때의 샘플의 분산의 분포가 된다고 한다. 이게 정말 그런가 궁금해서, python scipy.stats 을 이용해서 실험을 해 보았다. (첫 문장에서 분산의 분포라고 했지만, 사실 제곱합의 분포다. 평균이 0인 확률변수의 분산은 결국 제곱합/k 일 뿐이니까 이렇게 퉁치자.)
import numpy as np
import pandas as pd
import scipy as sc
import scipy.stats
import seaborn as sns
import matplotlib.pyplot as plt
dist = scipy.stats.norm()
def plot_chisq(df, ax):
x = np.linspace(0, 20, 399)
ax.plot(x, scipy.stats.chi2.pdf(x, df))
def do(n_sample):
xs = []
ms = []
xsqs = []
for _ in range(200000):
x = dist.rvs(n_sample)
xs.append(x)
ms.append(x.mean())
xsqs.append((x*x).sum())
xs = np.array(xs)
ms = np.array(ms)
xsqs = np.array(xsqs)
f, axes = plt.subplots(2, 1, figsize=(12, 12))
sns.distplot(ms, ax=axes[1])
plot_chisq(n_sample, axes[0])
sns.distplot(xsqs, ax=axes[0])
#plt.show()
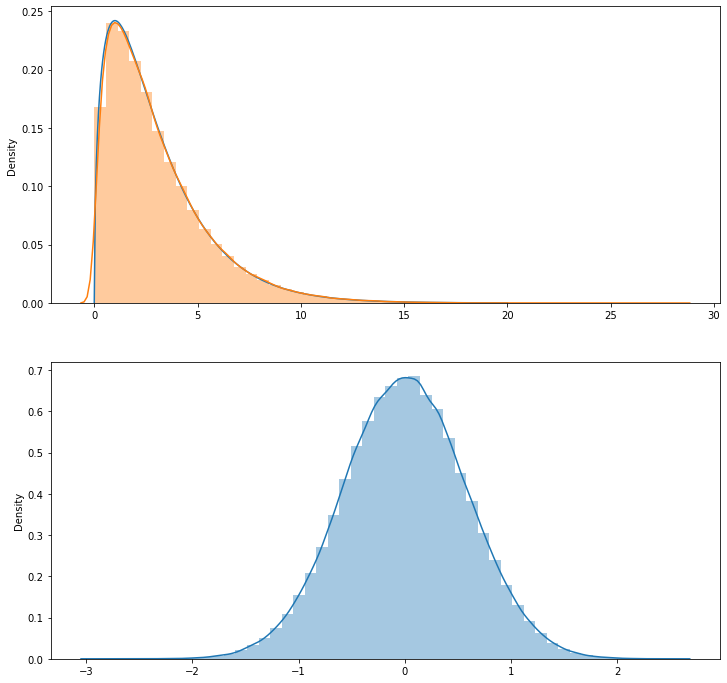
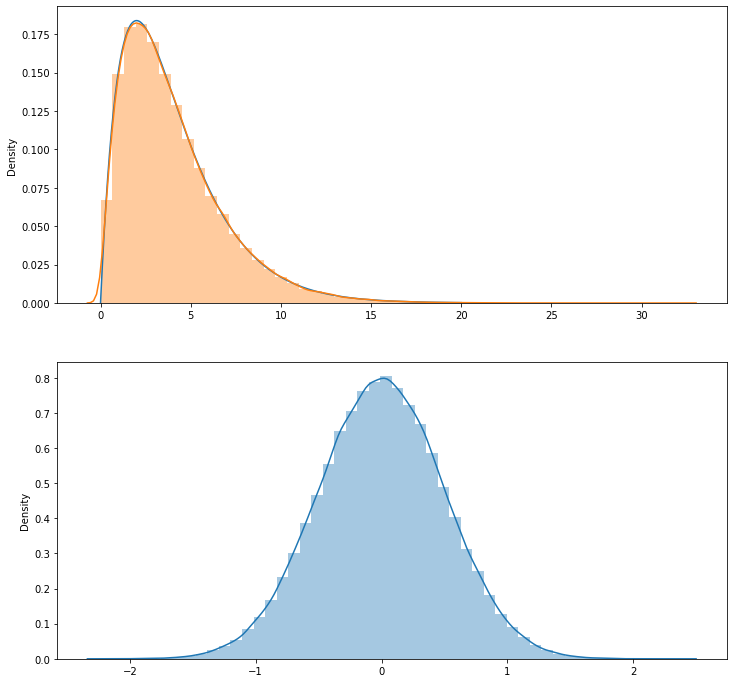
코드를 설명해 보면, do 함수 안을 보면 된다. for 루프에서 n_sample 개의 표본을 여러번(20만번) 뽑아서, 매번 뽑은 샘플의 평균과 변수 x의 제곱합을 리스트에 저장한다. 샘플을 뽑는 모집단이 표준정규분포를 따르기 때문에, 평균이 0이다. 그래서 x의 제곱합은 분산이 스케일된 값이다.
이렇게 모은 두가지 데이터를 seaborn 의 distplot 을 통해 히스토그램을 그려본다. 분포에 대한 피팅곡선까지 그려주니까, 그 피팅곡선과 수학적인 카이제곱( chi^2 ) 분포 그래프와 비교해 볼 수 있다.
나는 위 코드를 jupyter 에서 실행했기 때문에, plt.show() 가 필요 없었지만, .py 스크립트로 실행할 때에는 plt.show() 가 필요하다.
결과로 나온 그래프는 다음과 같다. k=1부터 5까지 그래프를 그려본 것이다. 공히 아랫쪽의 평균분포는 정규분포의 모양임을 알 수 있고, 위쪽의 분산분포 그래프에서 붉은색 피팅곡선과 카이제곱분포 수식 그래프가 상당히 일치하는 것을 볼 수 있다.



728x90
'프로그래밍 > Python' 카테고리의 다른 글
| 엘라스틱서치 elasticsearch-py, elasticsearch-dsl 에서 검색결과를 모두 가져오기. (덤 pandasticsearch) (0) | 2020.12.24 |
|---|---|
| [Anaconda] conda install 과 pip install 은 똑같은 걸까? (0) | 2020.12.23 |
| [통계학|Scipy] scipy 로 정규분포 그래프 + 구간확률 구하기. (0) | 2020.12.10 |
| 윈도우용 파이썬 3.8 버전에서 pip install kivy 로 설치가 안 된다. (0) | 2020.12.09 |
| [Python] 윈도우 cmd 창에서 python 을 입력하면 윈도우 스토어 설치화면이 나온다. (0) | 2020.12.05 |

