 [Python|Numpy|Matplotlib] 푸리에 시리즈 사각파
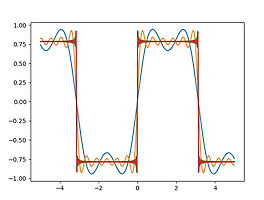
10년전 포스팅에 C로 사각파 푸리에 시리즈를 구현한 것이 있었다. 이걸 파이썬, numpy, matplotlib 를 이용해 다시 구현해 본다. import numpy as np import matplotlib.pyplot as plt def F(n, X): """ 1 F (t) = ------- sin ( (2n+1) t ) n 2n + 1 """ return np.sin((2*n+1)*X)/(2*n+1) def RectWave(n, X): """ n Sigma F (t) k=1 """ y = np.zeros(X.shape) for k in range(n+1): y = F(k, X) + y return y X = np.linspace(-5, 5, 1000) for i in (1, 5, 50, 100):..
[Python|Numpy|Matplotlib] 푸리에 시리즈 사각파
10년전 포스팅에 C로 사각파 푸리에 시리즈를 구현한 것이 있었다. 이걸 파이썬, numpy, matplotlib 를 이용해 다시 구현해 본다. import numpy as np import matplotlib.pyplot as plt def F(n, X): """ 1 F (t) = ------- sin ( (2n+1) t ) n 2n + 1 """ return np.sin((2*n+1)*X)/(2*n+1) def RectWave(n, X): """ n Sigma F (t) k=1 """ y = np.zeros(X.shape) for k in range(n+1): y = F(k, X) + y return y X = np.linspace(-5, 5, 1000) for i in (1, 5, 50, 100):..


